Pseudotime analysis with Monocle 2
Lambda Moses
2020-02-07
Last updated: 2020-02-07
Checks: 7 0
Knit directory: BUSpaRse_notebooks/
This reproducible R Markdown analysis was created with workflowr (version 1.6.0). The Checks tab describes the reproducibility checks that were applied when the results were created. The Past versions tab lists the development history.
Great! Since the R Markdown file has been committed to the Git repository, you know the exact version of the code that produced these results.
Great job! The global environment was empty. Objects defined in the global environment can affect the analysis in your R Markdown file in unknown ways. For reproduciblity it’s best to always run the code in an empty environment.
The command set.seed(20181214) was run prior to running the code in the R Markdown file. Setting a seed ensures that any results that rely on randomness, e.g. subsampling or permutations, are reproducible.
Great job! Recording the operating system, R version, and package versions is critical for reproducibility.
Nice! There were no cached chunks for this analysis, so you can be confident that you successfully produced the results during this run.
Great job! Using relative paths to the files within your workflowr project makes it easier to run your code on other machines.
Great! You are using Git for version control. Tracking code development and connecting the code version to the results is critical for reproducibility. The version displayed above was the version of the Git repository at the time these results were generated.
Note that you need to be careful to ensure that all relevant files for the analysis have been committed to Git prior to generating the results (you can use wflow_publish or wflow_git_commit). workflowr only checks the R Markdown file, but you know if there are other scripts or data files that it depends on. Below is the status of the Git repository when the results were generated:
Ignored files:
Ignored: .Rhistory
Ignored: .Rproj.user/
Ignored: BUSpaRse_notebooks.Rproj
Ignored: MouseMineSynteny.blocks.gz
Ignored: NCBI_Human_forSynteny.gff3.gz
Ignored: data/fastqs/
Ignored: data/hgmm_100_fastqs.tar
Ignored: data/hgmm_1k_fastqs.tar
Ignored: data/hgmm_1k_v3_fastqs.tar
Ignored: data/hgmm_1k_v3_fastqs/
Ignored: data/hs_cdna.fa.gz
Ignored: data/hs_cdna96.fa.gz
Ignored: data/mm_cdna.fa.gz
Ignored: data/mm_cdna96.fa.gz
Ignored: data/mm_cdna97.fa.gz
Ignored: data/neuron_10k_v3_fastqs.tar
Ignored: data/neuron_10k_v3_fastqs/
Ignored: data/retina/
Ignored: data/whitelist_v2.txt
Ignored: data/whitelist_v3.txt
Ignored: output/hs_mm_tr_index.idx
Ignored: output/hs_mm_tr_index96.idx
Ignored: output/mm_cDNA_introns_97.idx
Ignored: output/mm_cDNA_introns_97_collapse.idx
Ignored: output/mm_tr_index.idx
Ignored: output/mm_tr_index97.idx
Ignored: output/out_hgmm1k2/
Ignored: output/out_hgmm1k_v3/
Ignored: output/out_pbmc1k/
Ignored: output/out_retina/
Ignored: tmp/
Untracked files:
Untracked: .ipynb_checkpoints/
Untracked: SRR7244429_1.fastq
Untracked: SRR7244429_2.fastq
Untracked: analysis/dropseq_retina.Rmd
Untracked: analysis/ee_ie_junctions.Rmd
Untracked: analysis/junction.Rmd
Untracked: analysis/junction2.Rmd
Untracked: human_mouse_transcript_to_gene.tsv
Untracked: output/ee_ie/
Untracked: output/neuron10k/
Untracked: output/neuron10k_collapse/
Untracked: output/neuron10k_junction/
Untracked: output/neuron10k_velocity/
Untracked: output/out_hgmm1k/
Untracked: output/tr2g_hgmm.tsv
Untracked: output/tr2g_mm97.tsv
Untracked: problem5.ipynb
Untracked: test/
Unstaged changes:
Deleted: colab/.ipynb_checkpoints/10xv3-checkpoint.ipynb
Deleted: colab/.ipynb_checkpoints/Monocle 2-checkpoint.ipynb
Deleted: colab/.ipynb_checkpoints/Slingshot-checkpoint.ipynb
Deleted: colab/10xv3.ipynb
Deleted: colab/Mixed species (10x v2 chemistry).ipynb
Deleted: colab/Monocle 2.ipynb
Deleted: colab/Slingshot.ipynb
Note that any generated files, e.g. HTML, png, CSS, etc., are not included in this status report because it is ok for generated content to have uncommitted changes.
These are the previous versions of the R Markdown and HTML files. If you’ve configured a remote Git repository (see ?wflow_git_remote), click on the hyperlinks in the table below to view them.
| File | Version | Author | Date | Message |
|---|---|---|---|---|
| Rmd | f52668f | Lambda Moses | 2020-02-07 | Link to Google Colab version |
| html | f6d94b4 | Lambda Moses | 2020-02-01 | Build site. |
| Rmd | 46a046e | Lambda Moses | 2020-02-01 | SingleR’s interface changed after getting to Bioconductor |
| html | d5c995e | Lambda Moses | 2020-01-18 | Build site. |
| Rmd | 6d7db78 | Lambda Moses | 2020-01-18 | Added section for kb and updated for Bioconductor 3.10 |
| Rmd | aa22abe | GitHub | 2019-07-26 | Update monocle2.Rmd |
| html | a1bf016 | Lambda Moses | 2019-07-25 | Build site. |
| Rmd | 4a9691a | Lambda Moses | 2019-07-25 | Reran with Ensembl 97 |
| html | 2da533f | Lambda Moses | 2019-07-16 | Build site. |
| Rmd | 6edf827 | Lambda Moses | 2019-07-16 | Just realized that one of the plots isn’t showing because of a typo |
| html | 62a20a3 | Lambda Moses | 2019-07-16 | Build site. |
| Rmd | 3cf75fe | Lambda Moses | 2019-07-16 | Added Monocle 2 notebook |
In this vignette, we will process fastq files of the 10x 10k neurons from an E18 mouse with the kallisto | bustools workflow, and perform pseudotime analysis with Monocle 2 on the neuronal cell types. Monocle 2 is deprecated, but it can be easily installed from Bioconductor and still has a user base. At present, Monocle 3 is at beta stage of development, and it can be hard to install on Linux servers due to gdal dependency.
Setup
If you would like to rerun this notebook, you can git clone this repository or use the Google colab version of this notebook. The Google Colab version uses the 10x 1k neurons dataset and the kb wrapper of kallisto and bustools to make that notebook more interactive (the slowest step is installing packages). This static version shows the individual kallisto and bustools commands, which may be helpful for modularization of the workflow.
Install packages
This notebook demonstrates the use of command line tools kallisto and bustools. Please use kallisto >= 0.46, whose binary can be downloaded here. The binary of bustools can be found here.
After you download the binary, you should decompress the file (if it is tar.gz) with tar -xzvf file.tar.gz in the bash terminal, and add the directory containing the binary to PATH by export PATH=$PATH:/foo/bar, where /foo/bar is the directory of interest. Then you can directly invoke the binary on the command line as we will do in this notebook.
We will be using the R packages below. BUSpaRse is now on Bioconductor 3.10. For Mac users, see the installation note for BUSpaRse. BUSpaRse will be used to generate the transcript to gene file for bustools and to read output of bustools into R. We will use SingleR, which is also on Bioconductor 3.10 to annotate cell types. We’ll use Bioconductor package scater, which is based on SingleCellExperiment, for QC.
This vignette uses the version of DropletUtils from Bioconductor version 3.10; the version from Bioconductor 3.8 has a different user interface. If you are using a version of R older than 3.6.0 and want to rerun this vignette, then you can adapt the knee plot code to the older version of DropletUtils or install DropletUtils from GitHub. The package monocle should also be installed from Bioconductor:
if (!require(BiocManager)) {
install.packages("BiocManager")
}
BiocManager::install(c("DropletUtils", "monocle", "SingleR", "BUSpaRse", "scater", "scran"))The other R packages below are on CRAN.
library(scater)
library(BUSpaRse)
library(DropletUtils)
library(monocle)
library(SingleR)
library(Matrix)
library(tidyverse)
theme_set(theme_bw())Download data
The dataset we are using is 10x 10k neurons from an E18 mouse (almost 25 GB).
# Download data
if (!file.exists("./data/neuron_10k_v3_fastqs.tar")) {
download.file("http://s3-us-west-2.amazonaws.com/10x.files/samples/cell-exp/3.0.0/neuron_10k_v3/neuron_10k_v3_fastqs.tar", "./data/neuron_10k_v3_fastqs.tar", method = "wget", quiet = TRUE)
}cd ./data
tar -xvf ./neuron_10k_v3_fastqs.tarGenerate the gene count matrix
Build the kallisto index
Here we use kallisto to pseudoalign the reads to the transcriptome and then to create the bus file to be converted to a sparse matrix. The first step is to build an index of the mouse transcriptome. The transcriptome downloaded here is Ensembl version 97.
# Mouse transcriptome
if (!file.exists("./data/mm_cdna97.fa.gz")) {
download.file("ftp://ftp.ensembl.org/pub/release-97/fasta/mus_musculus/cdna/Mus_musculus.GRCm38.cdna.all.fa.gz", "./data/mm_cdna97.fa.gz", method = "wget", quiet = TRUE)
}kallisto index -i ./output/mm_tr_index97.idx ./data/mm_cdna97.fa.gzMap transcripts to genes
For the sparse matrix, most people are interested in how many UMIs per gene per cell, we here we will quantify this from the bus output, and to do so, we need to find which gene corresponds to each transcript. Remember in the output of kallisto bus, there’s the file transcripts.txt. Those are the transcripts in the transcriptome index.
Remember that we downloaded transcriptome FASTA file from Ensembl just now. In FASTA files, each entry is a sequence with a name. In Ensembl FASTA files, the sequence name has genome annotation of the corresponding sequence, so we can extract transcript IDs and corresponding gene IDs and gene names from there.
tr2g <- transcript2gene(fasta_file = "./data/mm_cdna97.fa.gz",
kallisto_out_path = "./output/neuron10k",
verbose = FALSE)head(tr2g)#> transcript gene gene_name
#> 1: ENSMUST00000196221.1 ENSMUSG00000096749.2 Trdd1
#> 2: ENSMUST00000179664.1 ENSMUSG00000096749.2 Trdd1
#> 3: ENSMUST00000177564.1 ENSMUSG00000096176.1 Trdd2
#> 4: ENSMUST00000178537.1 ENSMUSG00000095668.1 Trbd1
#> 5: ENSMUST00000178862.1 ENSMUSG00000094569.1 Trbd2
#> 6: ENSMUST00000179520.1 ENSMUSG00000094028.1 Ighd4-1bustools requires tr2g to be written into a tab delimited file of a specific format: No headers, first column is transcript ID, and second column is the corresponding gene ID. Transcript IDs must be in the same order as in the kallisto index.
# Write tr2g to format required by bustools
save_tr2g_bustools(tr2g, file_save = "./output/tr2g_mm97.tsv")With the index and the fastq files, the kallisto bus command generates a binary bus file called output.bus, which will be sorted and processed to generate a gene count matrix.
cd ./data/neuron_10k_v3_fastqs
kallisto bus -i ../../output/mm_tr_index97.idx -o ../../output/neuron10k -x 10xv3 -t8 \
neuron_10k_v3_S1_L002_R1_001.fastq.gz neuron_10k_v3_S1_L002_R2_001.fastq.gz \
neuron_10k_v3_S1_L001_R1_001.fastq.gz neuron_10k_v3_S1_L001_R2_001.fastq.gzRun bustools
A whitelist that contains all the barcodes known to be present in the kit is provided by 10x and comes with CellRanger. A CellRanger installation is required, though we will not run CellRanger here.
cp ~/cellranger-3.0.2/cellranger-cs/3.0.2/lib/python/cellranger/barcodes/3M-february-2018.txt.gz \
./data/whitelist_v3.txt.gz
gunzip ./data/whitelist_v3.txt.gzThen we’re ready to make the gene count matrix. First, bustools runs barcode error correction on the bus file. Then, the corrected bus file is sorted by barcode, UMI, and equivalence classes. Then the UMIs are counted and the counts are collapsed into gene level. Here the | is pipe in bash, just like the magrittr pipe %>% in R, that pipes the output of one command to the next.
mkdir ./tmp
bustools correct -w ./data/whitelist_v3.txt -p ./output/neuron10k/output.bus | \
bustools sort -T tmp/ -t4 -p - | \
bustools count -o ./output/neuron10k/genes -g ./output/tr2g_mm97.tsv \
-e ./output/neuron10k/matrix.ec -t ./output/neuron10k/transcripts.txt --genecounts -
rm -r ./tmpThe outputs are explained in the 10xv2 vignette.
Preprocessing
Now we can load the matrix into R for analysis.
res_mat <- read_count_output("./output/neuron10k", name = "genes", tcc = FALSE)Remove empty droplets
dim(res_mat)#> [1] 36558 1413171The number of genes seems reasonable. The number of barcodes is way larger than the expected ~10k.
tot_counts <- Matrix::colSums(res_mat)
summary(tot_counts)#> Min. 1st Qu. Median Mean 3rd Qu. Max.
#> 0.00 1.00 1.00 64.98 2.00 51636.00The vast majority of “cells” have only no or just a few UMI detected. Those are empty droplets. 10x claims to have cell capture rate of up to 65%, but in practice, depending on how many cells are in fact loaded, the rate can be much lower. A commonly used method to estimate the number of empty droplets is barcode ranking knee and inflection points, as those are often assumed to represent transition between two components of a distribution. While more sophisticated methods exist (e.g. see emptyDrops in DropletUtils), for simplicity, we will use the barcode ranking method here. However, whichever way we go, we don’t have the ground truth.
# Compute barcode rank
bc_rank <- barcodeRanks(res_mat, lower = 1000)#' Knee plot for filtering empty droplets
#'
#' Visualizes the inflection point to filter empty droplets. This function plots
#' different datasets with a different color. Facets can be added after calling
#' this function with `facet_*` functions.
#'
#' @param bc_rank A `DataFrame` output from `DropletUtil::barcodeRanks`.
#' @return A ggplot2 object.
knee_plot <- function(bc_rank) {
knee_plt <- tibble(rank = bc_rank[["rank"]],
total = bc_rank[["total"]]) %>%
distinct() %>%
dplyr::filter(total > 0)
annot <- tibble(inflection = metadata(bc_rank)[["inflection"]],
rank_cutoff = max(bc_rank$rank[bc_rank$total > metadata(bc_rank)[["inflection"]]]))
p <- ggplot(knee_plt, aes(rank, total)) +
geom_line() +
geom_hline(aes(yintercept = inflection), data = annot, linetype = 2) +
geom_vline(aes(xintercept = rank_cutoff), data = annot, linetype = 2) +
scale_x_log10() +
scale_y_log10() +
labs(x = "Rank", y = "Total UMIs")
return(p)
}Here the knee plot is transposed, because this is more generalizable to multi-modal data, such that those with not only RNA-seq but also abundance of cell surface markers. In that case, we can plot number of UMIs on the x axis, number of cell surface protein tags on the y axis, and barcode rank based on both UMI and protein tag counts on the z axis; it makes more sense to make barcode rank the dependent variable. See this blog post by Lior Pachter for a more detailed explanation.
knee_plot(bc_rank) + coord_flip()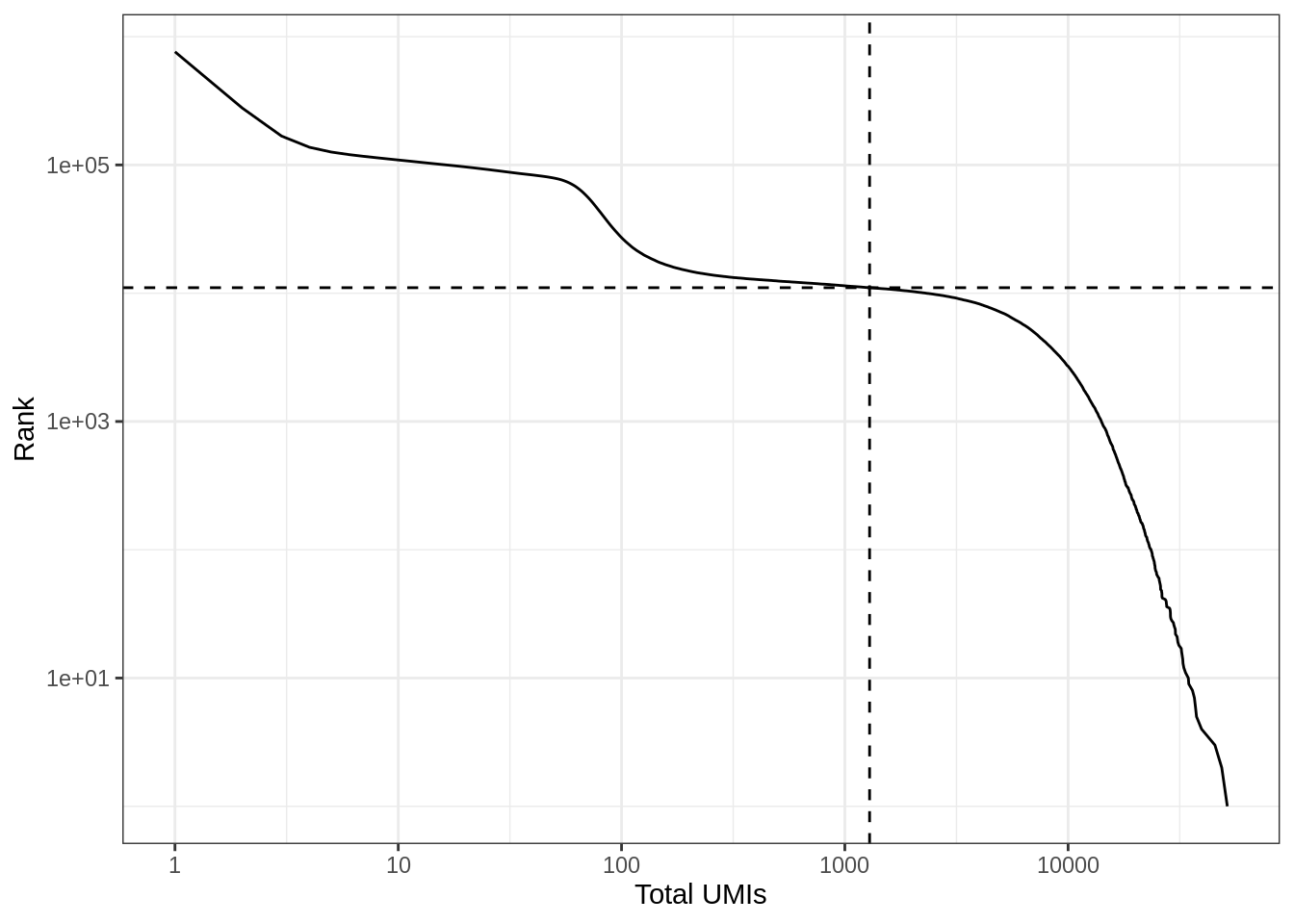
# Remove genes that are not detected and empty droplets
res_mat <- res_mat[Matrix::rowSums(res_mat) > 0, tot_counts > metadata(bc_rank)$inflection]
dim(res_mat)#> [1] 23516 11037Now the number of cells is closer to expectation.
rownames(res_mat) <- str_remove(rownames(res_mat), "\\.\\d+")Cell type inference
Monocle 2 only infers one trajectory for the entire dataset, so non-neuronal cells like endothelial cells and erythrocytes may be mistaken as highly differentiated cells from the neuronal lineage. So we will remove cell types not of the neural or glial lineages. Cell types are also helpful to orient the trajectory; neuronal progenitor cells must come before neurons. Here cell type inference is done programatically with SingleR, which compares gene expression profiles of individual cells to bulk RNA-seq data of purified known cell types.
mouse.rnaseq <- MouseRNAseqData(ensembl = TRUE)#> snapshotDate(): 2019-10-22#> see ?SingleR and browseVignettes('SingleR') for documentation#> loading from cache#> see ?SingleR and browseVignettes('SingleR') for documentation#> loading from cache#> snapshotDate(): 2019-10-29#> loading from cache#> require("ensembldb")#> Warning: Unable to map 2180 of 21214 requested IDs.sce <- SingleCellExperiment(assays = list(counts = res_mat))
sce <- logNormCounts(sce)Then SingleR will assign each cell a label based on Spearman correlation with known cell types from bulk RNA-seq. These are meanings of the acronyms:
- OPCs: Oligodendrocyte progenitor cells
- NPCs: Neural progenitor cells
- aNSCs: Active neural stem cells
- qNSCs: Quiescent neural stem cells
annots <- SingleR(sce, ref = mouse.rnaseq, labels = colData(mouse.rnaseq)$label.fine,
de.method = "wilcox", method = "single", BPPARAM = MulticoreParam(10))inds <- annots$pruned.labels %in% c("NPCs", "Neurons", "OPCs", "Oligodendrocytes",
"qNSCs", "aNSCs", "Astrocytes", "Ependymal")
# Only keep these cell types
cells_use <- row.names(annots)[inds]
sce <- sce[, cells_use]
sce$cell_type <- annots$pruned.labels[inds]QC
df <- perCellQCMetrics(sce)
colData(sce) <- cbind(colData(sce), df)Total counts per cell, grouped by cell type
plotColData(sce, x = "cell_type", y = "sum") +
labs(y = "Total UMI count", x = "Cell type")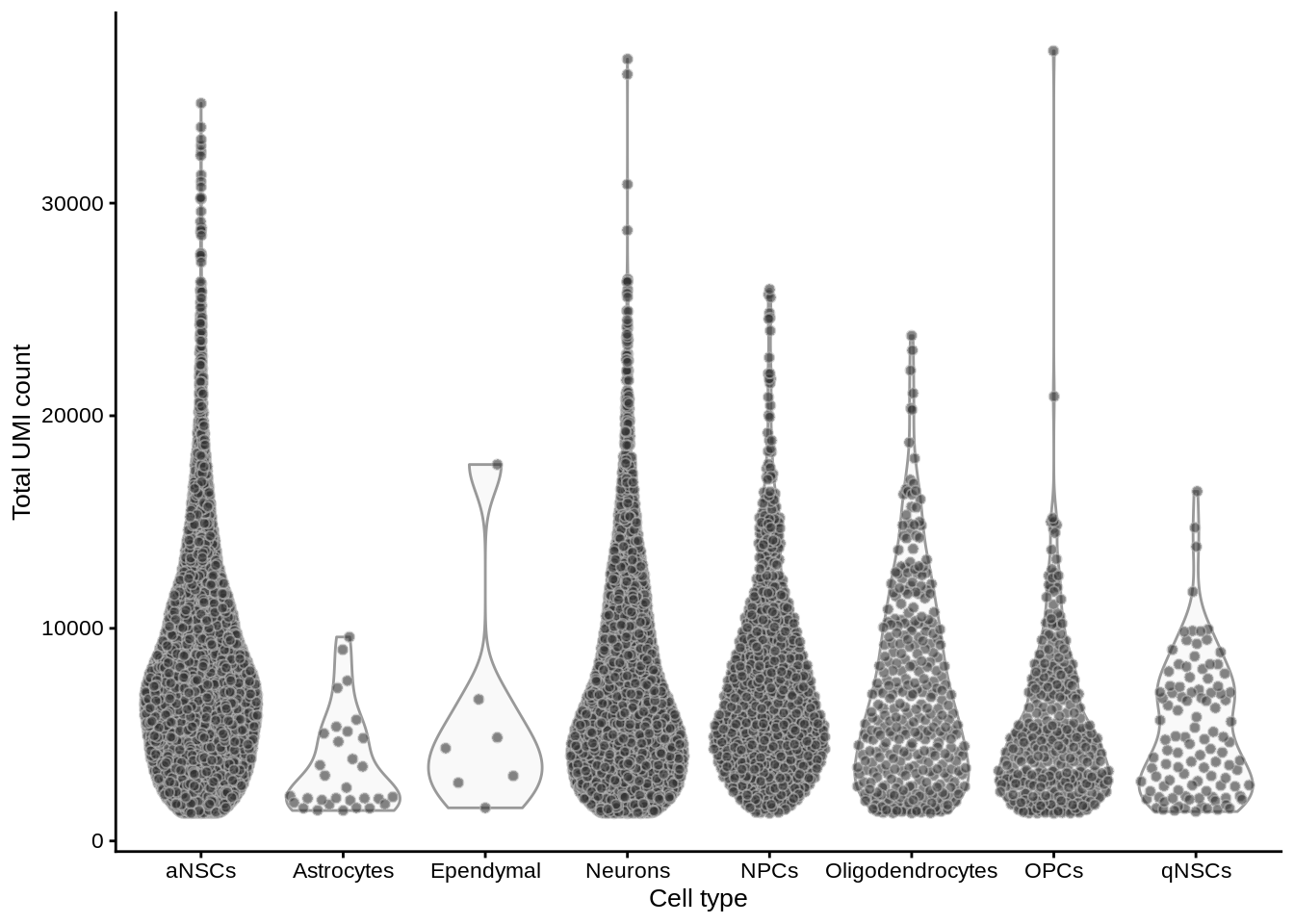
| Version | Author | Date |
|---|---|---|
| f6d94b4 | Lambda Moses | 2020-02-01 |
plotColData(sce, x = "cell_type", y = "detected") +
labs(y = "Number of genes detected", x = "Cell type")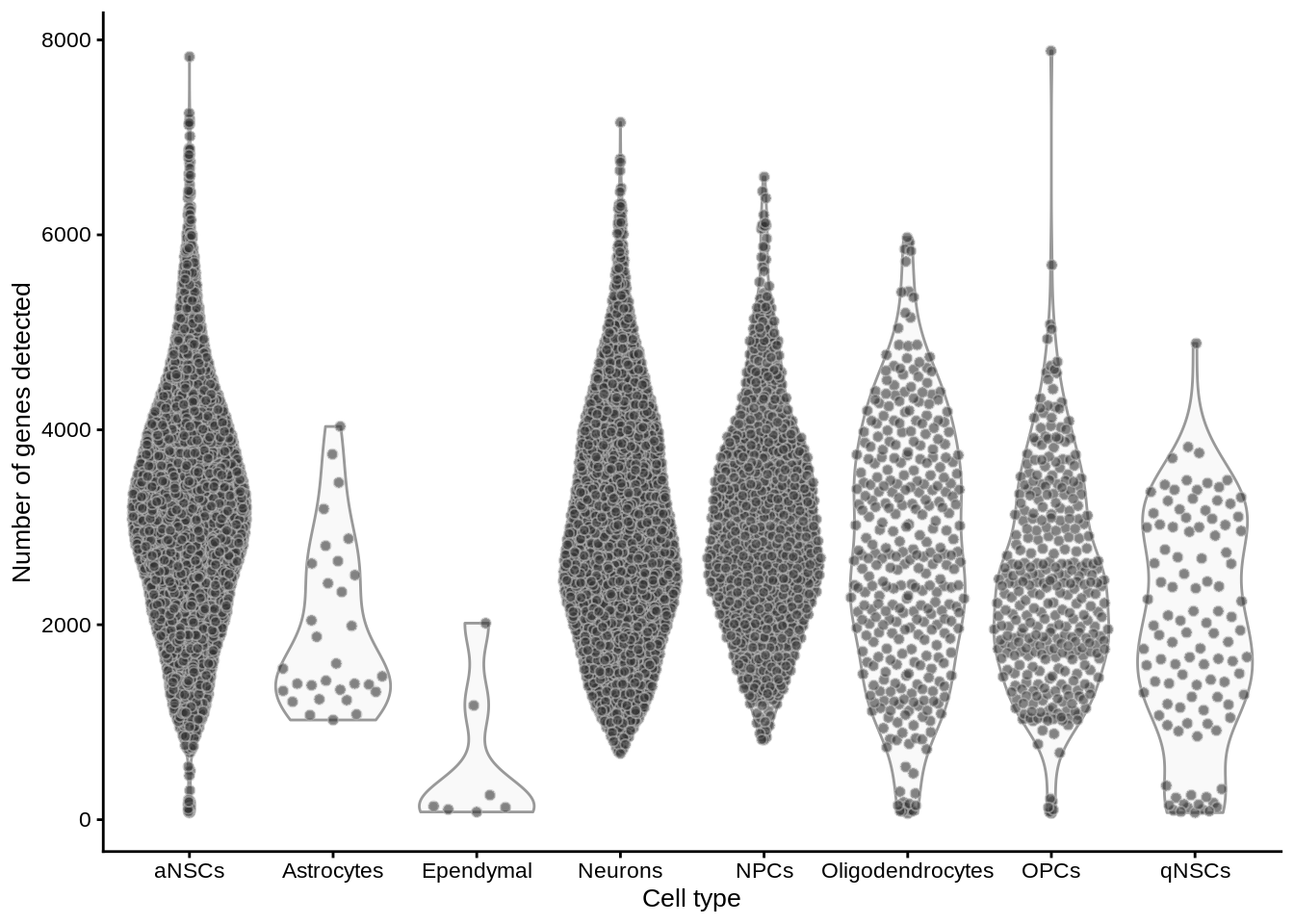
| Version | Author | Date |
|---|---|---|
| f6d94b4 | Lambda Moses | 2020-02-01 |
plotColData(sce, x = "sum", y = "detected", colour_by = "cell_type") +
scale_x_log10() +
scale_y_log10() +
annotation_logticks() +
labs(x = "Total UMI count", y = "Number of genes detected")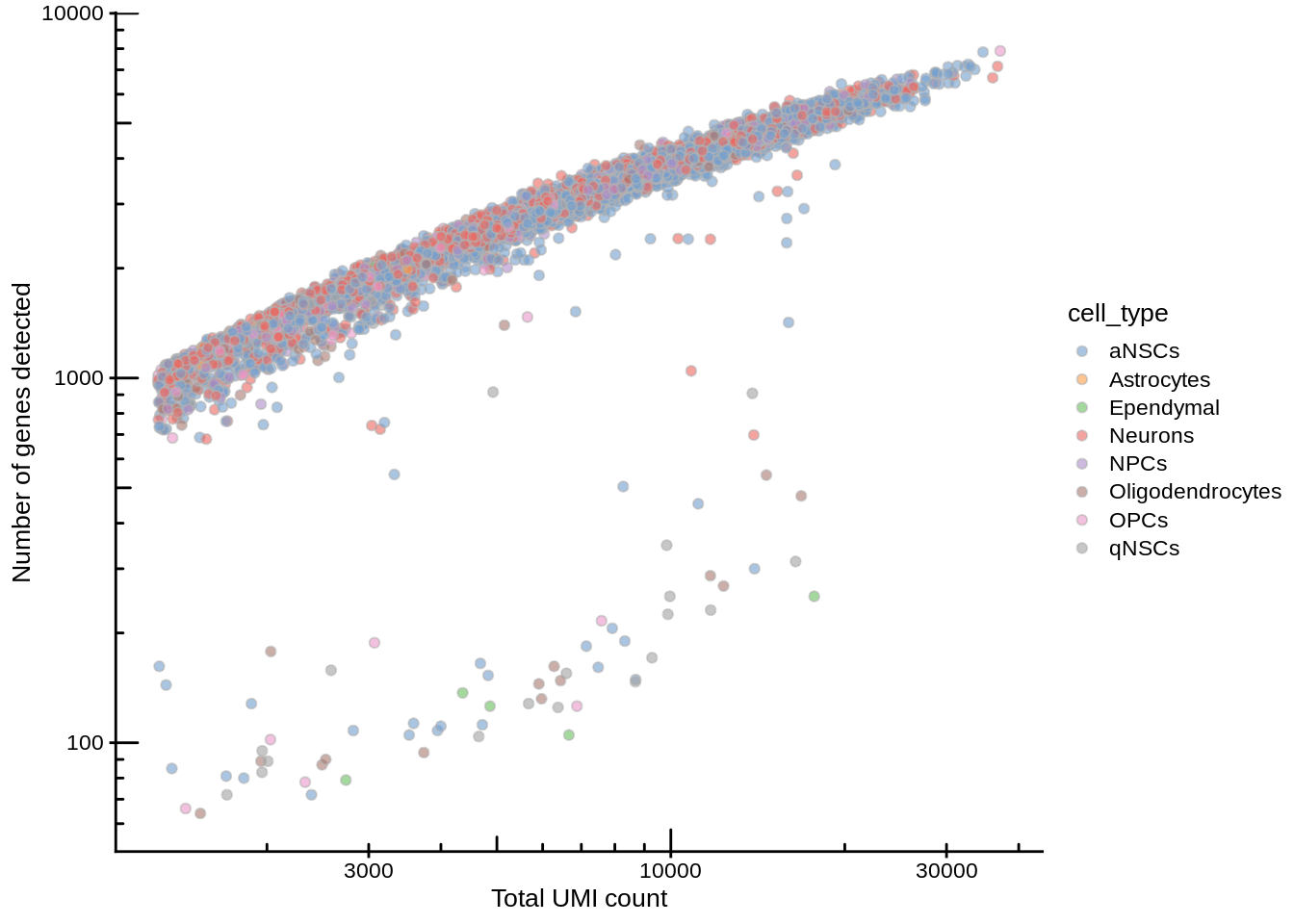
| Version | Author | Date |
|---|---|---|
| f6d94b4 | Lambda Moses | 2020-02-01 |
Monocle 2
# Construct CellDataSet object
pd <- data.frame(cell_id = cells_use,
cell_type = annots$pruned.labels[inds],
row.names = cells_use)
pd <- new("AnnotatedDataFrame", data = pd)
fd <- data.frame(gene_id = rownames(sce),
gene_short_name = tr2g$gene_name[match(rownames(sce), tr2g$gene)],
row.names = row.names(sce))
fd <- new("AnnotatedDataFrame", data = fd)
cds <- newCellDataSet(counts(sce), phenoData = pd, featureData = fd)Size factor and dispersion will be used to normalize data and select genes for clustering.
cds <- estimateSizeFactors(cds)
cds <- estimateDispersions(cds)#> Warning in log(ifelse(y == 0, 1, y/mu)): NaNs produced#> Warning: step size truncated due to divergence#> Warning in log(ifelse(y == 0, 1, y/mu)): NaNs produced#> Warning: step size truncated due to divergence#> Warning in log(ifelse(y == 0, 1, y/mu)): NaNs produced#> Warning: step size truncated due to divergence#> Warning: glm.fit: algorithm did not converge
#> Warning: glm.fit: algorithm did not converge#> Removing 100 outliersGenes that aren’t highly expressed enough will not be used for clustering, since they may not give meaningful signal and would only add noise.
disp_table <- dispersionTable(cds)
clustering_genes <- subset(disp_table, mean_expression >= 0.1)
cds <- setOrderingFilter(cds, clustering_genes$gene_id)cds <- reduceDimension(cds, num_dim = 40, reduction_method = 'tSNE')
cds <- clusterCells(cds, method = "louvain")
plot_cell_clusters(cds, cell_size = 0.5) +
theme(legend.position = "none") +
labs(x = "tSNE1", y = "tSNE2")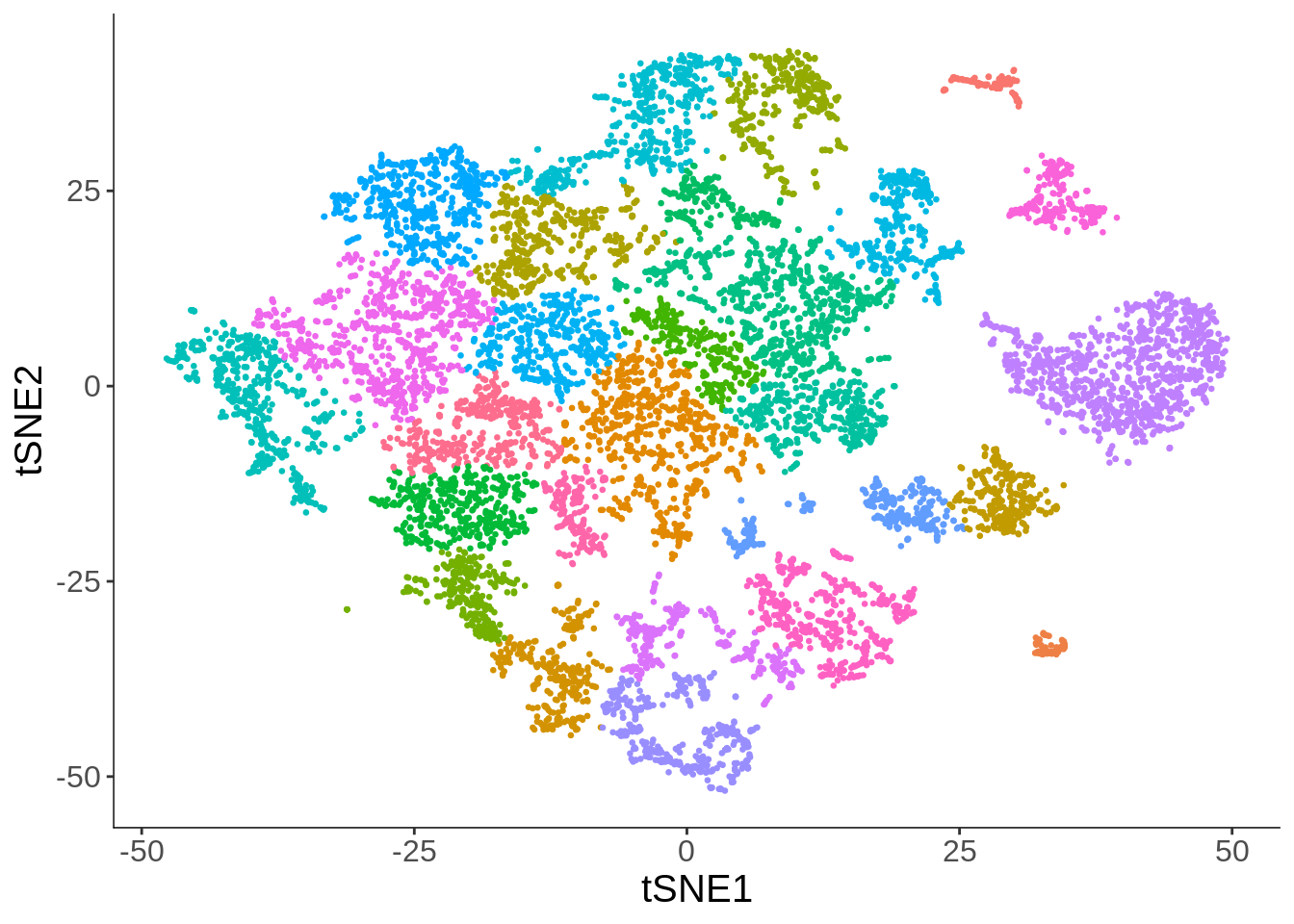
See where the annotated cell types are
plot_cell_clusters(cds, cell_size = 0.5, color_by = "cell_type") +
scale_color_brewer(name = "cell type", type = "qual", palette = "Set2") +
labs(x = "tSNE1", y = "tSNE2") +
theme(legend.position = "right") +
guides(color = guide_legend(override.aes = list(size = 3)))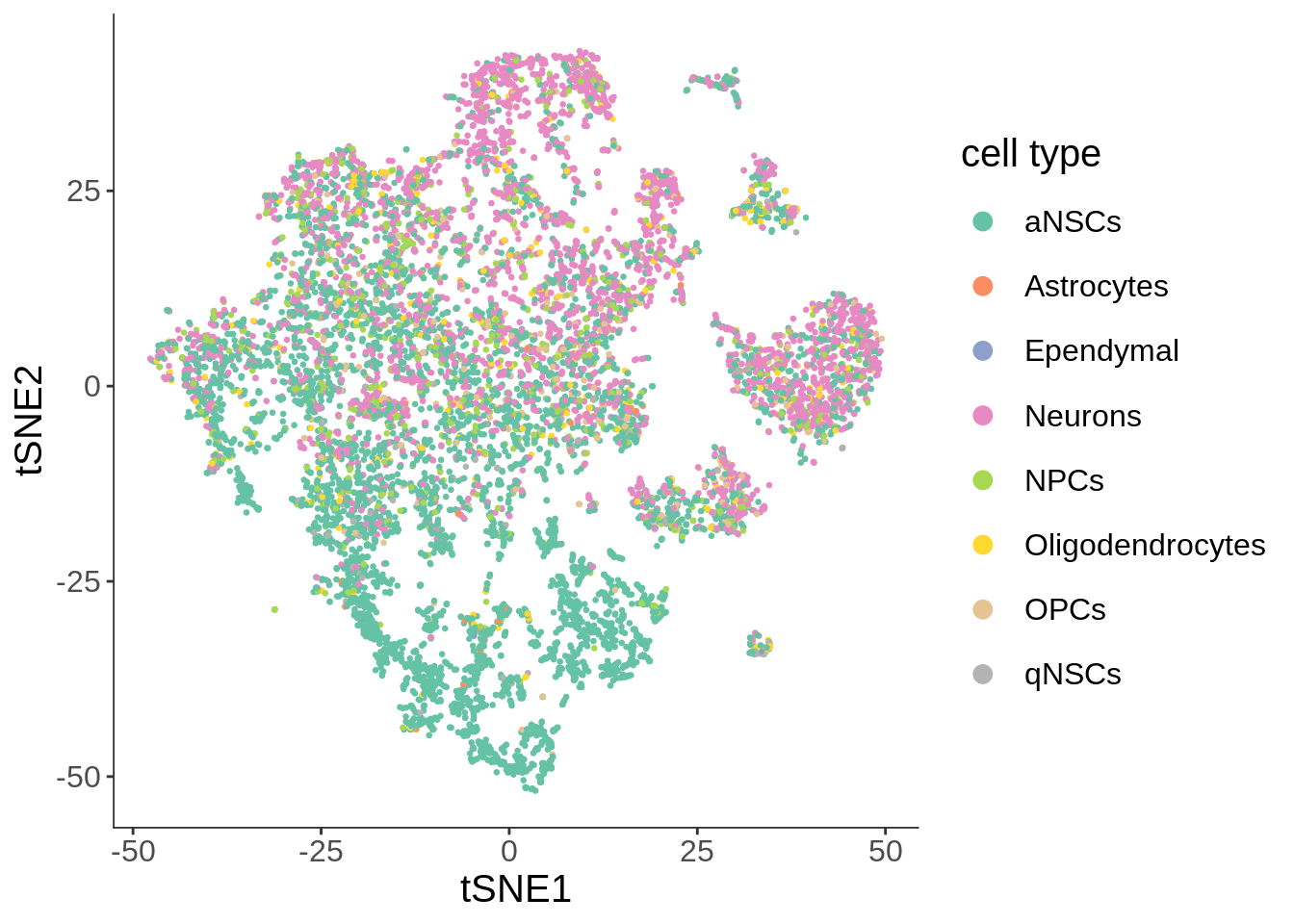
Genes likely to be informative of ordering of cells along the pseudotime trajectory will be selected for pseudotime inference.
diff_genes <- differentialGeneTest(cds, fullModelFormulaStr = "~ Cluster + cell_type",
cores = 10)
# Use top 3000 differentially expressed genes
ordering_genes <- row.names(subset(diff_genes, qval < 1e-3))[order(diff_genes$qval)][1:3000]
cds <- setOrderingFilter(cds, ordering_genes)Here Monocle 2 will first project the data to 2 dimensions with DDRTree, and then do trajectory inference (orderCells).
cds <- reduceDimension(cds, max_components = 2, method = 'DDRTree')
cds <- orderCells(cds)See what the trajectory looks like. This projection is DDRTree.
plot_cell_trajectory(cds, color_by = "cell_type", cell_size = 1) +
scale_color_brewer(name = "cell type", type = "qual", palette = "Set2")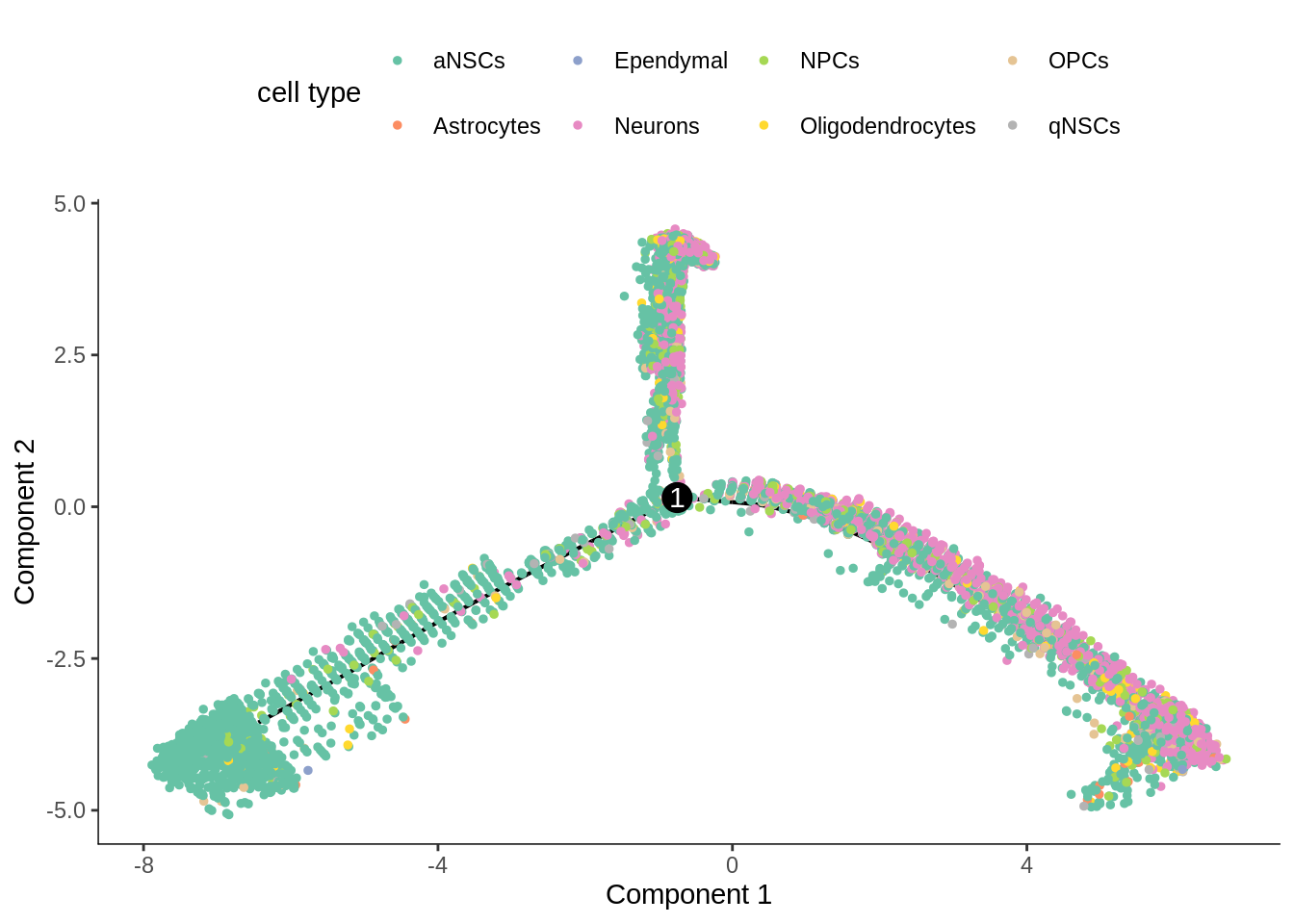
In the kallisto | bustools paper, I used slingshot for pseudotime analysis (Supplementary Figure 6.5) of this dataset, and found two neuronal end points. The result from Monocle 2 here also shows two main branches. Also, as expected, the stem cells are at the very beginning of the trajectory.
plot_cell_trajectory(cds, color_by = "Pseudotime", cell_size = 1) +
scale_color_viridis_c()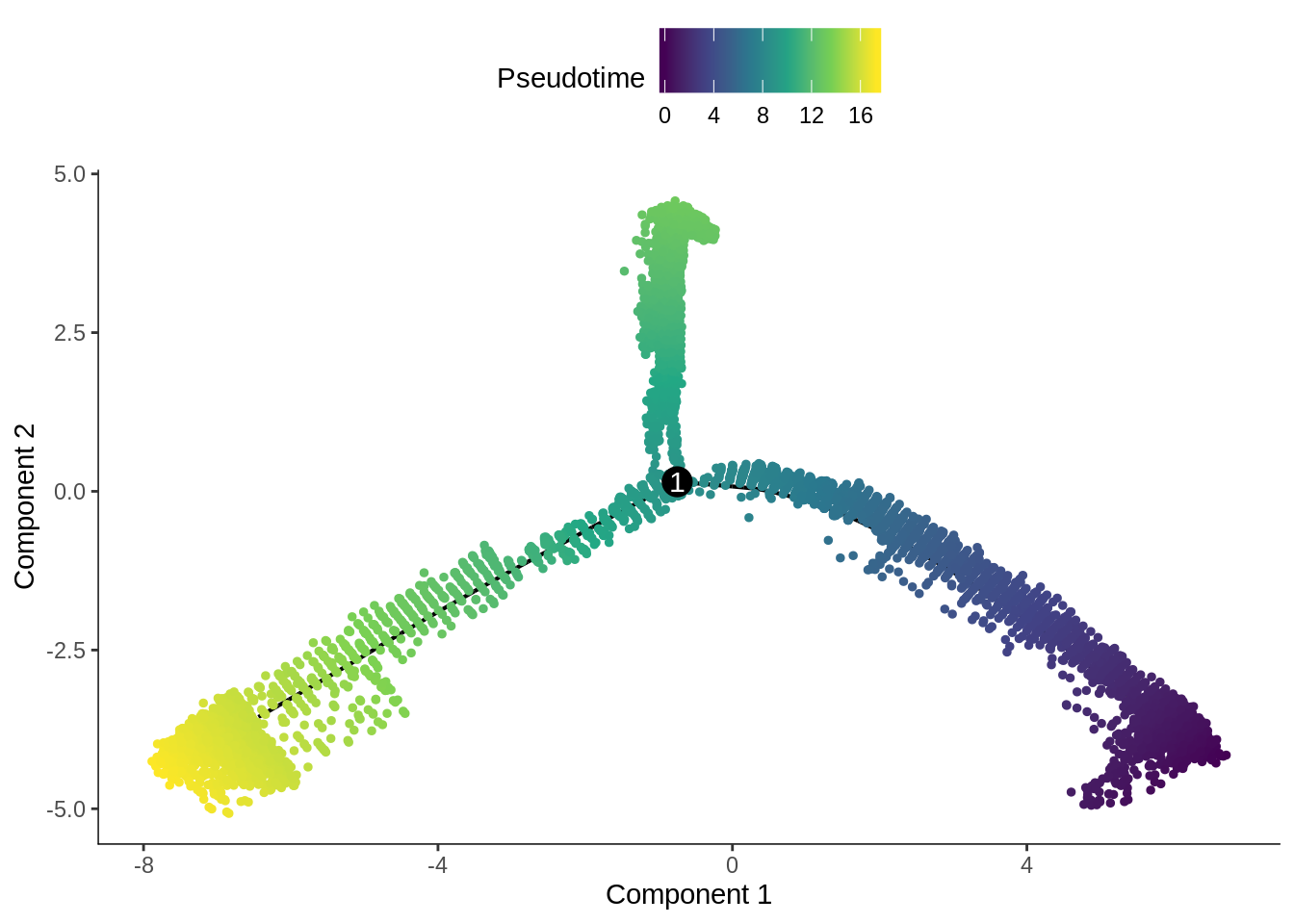
The pseudotime values are inverted.
cds <- orderCells(cds, reverse = TRUE)
plot_cell_trajectory(cds, color_by = "Pseudotime", cell_size = 1) +
scale_color_viridis_c()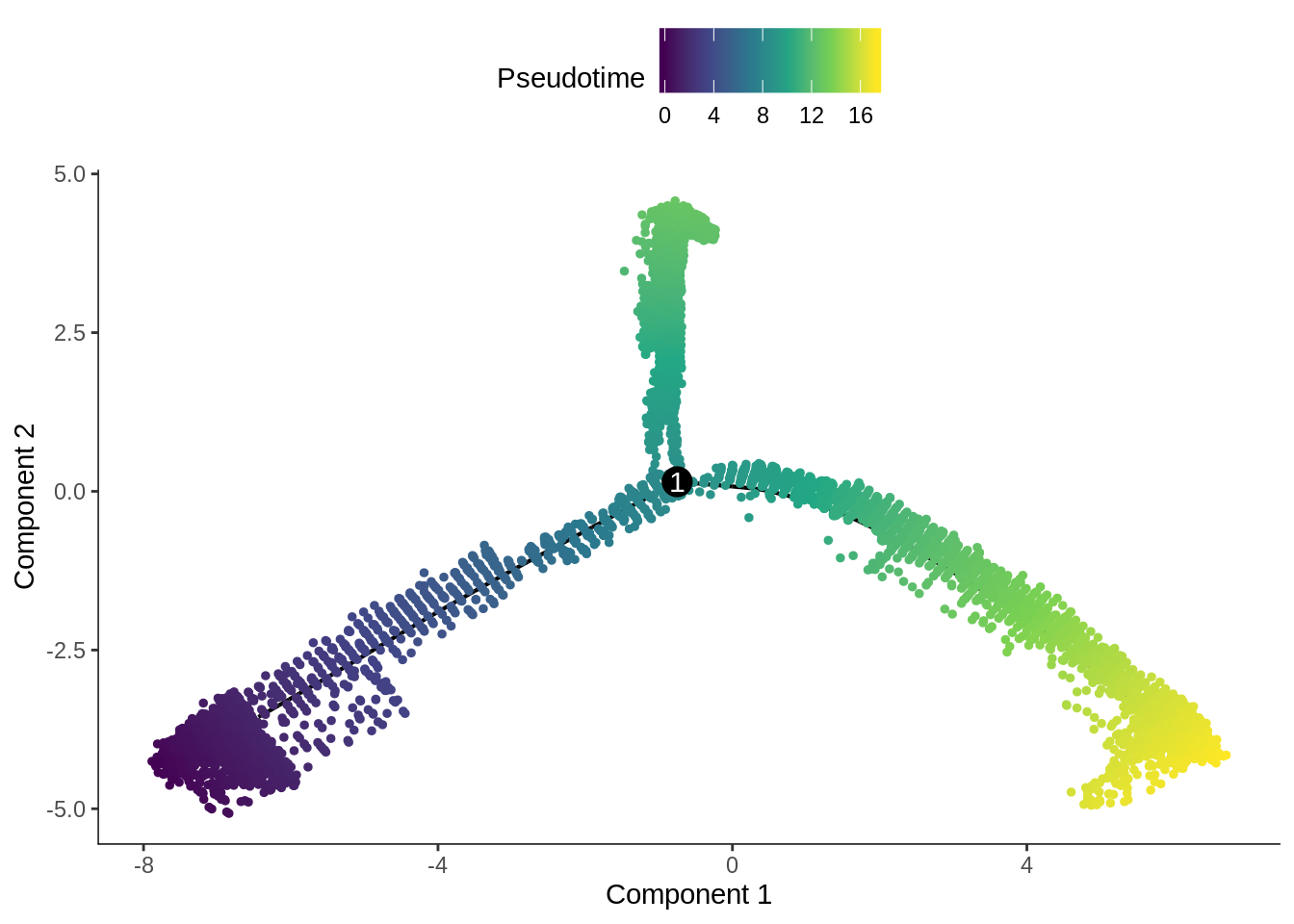
Monocle 2 can also be used to find genes differentially expressed along the pseudotime trajectory and clusters of such genes. See David Tang’s excellent Monocle 2 tutorial for how to use these functionalities.
sessionInfo()#> R version 3.6.0 (2019-04-26)
#> Platform: x86_64-redhat-linux-gnu (64-bit)
#> Running under: CentOS Linux 7 (Core)
#>
#> Matrix products: default
#> BLAS/LAPACK: /usr/lib64/R/lib/libRblas.so
#>
#> locale:
#> [1] en_US.UTF-8
#>
#> attached base packages:
#> [1] splines parallel stats4 stats graphics grDevices utils
#> [8] datasets methods base
#>
#> other attached packages:
#> [1] ensembldb_2.10.2 AnnotationFilter_1.10.0
#> [3] GenomicFeatures_1.38.1 AnnotationDbi_1.48.0
#> [5] forcats_0.4.0 stringr_1.4.0
#> [7] dplyr_0.8.3 purrr_0.3.3
#> [9] readr_1.3.1 tidyr_1.0.2
#> [11] tibble_2.1.3 tidyverse_1.3.0
#> [13] SingleR_1.0.5 monocle_2.14.0
#> [15] DDRTree_0.1.5 irlba_2.3.3
#> [17] VGAM_1.1-2 Matrix_1.2-18
#> [19] DropletUtils_1.6.1 BUSpaRse_1.0.0
#> [21] scater_1.14.6 ggplot2_3.2.1
#> [23] SingleCellExperiment_1.8.0 SummarizedExperiment_1.16.1
#> [25] DelayedArray_0.12.2 BiocParallel_1.20.1
#> [27] matrixStats_0.55.0 Biobase_2.46.0
#> [29] GenomicRanges_1.38.0 GenomeInfoDb_1.22.0
#> [31] IRanges_2.20.2 S4Vectors_0.24.3
#> [33] BiocGenerics_0.32.0 workflowr_1.6.0
#>
#> loaded via a namespace (and not attached):
#> [1] R.utils_2.9.2 tidyselect_1.0.0
#> [3] RSQLite_2.2.0 grid_3.6.0
#> [5] combinat_0.0-8 docopt_0.6.1
#> [7] Rtsne_0.15 munsell_0.5.0
#> [9] withr_2.1.2 colorspace_1.4-1
#> [11] fastICA_1.2-2 knitr_1.27
#> [13] rstudioapi_0.10 labeling_0.3
#> [15] git2r_0.26.1 slam_0.1-47
#> [17] GenomeInfoDbData_1.2.2 farver_2.0.3
#> [19] bit64_0.9-7 pheatmap_1.0.12
#> [21] rhdf5_2.30.1 rprojroot_1.3-2
#> [23] vctrs_0.2.2 generics_0.0.2
#> [25] xfun_0.12 BiocFileCache_1.10.2
#> [27] R6_2.4.1 ggbeeswarm_0.6.0
#> [29] rsvd_1.0.2 locfit_1.5-9.1
#> [31] bitops_1.0-6 assertthat_0.2.1
#> [33] promises_1.1.0 scales_1.1.0
#> [35] beeswarm_0.2.3 gtable_0.3.0
#> [37] rlang_0.4.3 zeallot_0.1.0
#> [39] rtracklayer_1.46.0 lazyeval_0.2.2
#> [41] broom_0.5.4 plyranges_1.6.6
#> [43] BiocManager_1.30.10 yaml_2.2.0
#> [45] reshape2_1.4.3 modelr_0.1.5
#> [47] backports_1.1.5 httpuv_1.5.2
#> [49] tools_3.6.0 RColorBrewer_1.1-2
#> [51] proxy_0.4-23 Rcpp_1.0.3
#> [53] plyr_1.8.5 progress_1.2.2
#> [55] zlibbioc_1.32.0 RCurl_1.98-1.1
#> [57] densityClust_0.3 prettyunits_1.1.1
#> [59] openssl_1.4.1 viridis_0.5.1
#> [61] cowplot_1.0.0 haven_2.2.0
#> [63] ggrepel_0.8.1 cluster_2.1.0
#> [65] fs_1.3.1 magrittr_1.5
#> [67] data.table_1.12.8 reprex_0.3.0
#> [69] RANN_2.6.1 whisker_0.4
#> [71] ProtGenerics_1.18.0 hms_0.5.3
#> [73] mime_0.8 evaluate_0.14
#> [75] xtable_1.8-4 XML_3.99-0.3
#> [77] sparsesvd_0.2 readxl_1.3.1
#> [79] gridExtra_2.3 HSMMSingleCell_1.6.0
#> [81] compiler_3.6.0 biomaRt_2.42.0
#> [83] crayon_1.3.4 R.oo_1.23.0
#> [85] htmltools_0.4.0 later_1.0.0
#> [87] RcppParallel_4.4.4 lubridate_1.7.4
#> [89] DBI_1.1.0 ExperimentHub_1.12.0
#> [91] dbplyr_1.4.2 rappdirs_0.3.1
#> [93] cli_2.0.1 R.methodsS3_1.7.1
#> [95] igraph_1.2.4.2 pkgconfig_2.0.3
#> [97] GenomicAlignments_1.22.1 xml2_1.2.2
#> [99] vipor_0.4.5 dqrng_0.2.1
#> [101] XVector_0.26.0 rvest_0.3.5
#> [103] digest_0.6.23 Biostrings_2.54.0
#> [105] cellranger_1.1.0 rmarkdown_2.1
#> [107] edgeR_3.28.0 DelayedMatrixStats_1.8.0
#> [109] curl_4.3 shiny_1.4.0
#> [111] Rsamtools_2.2.1 lifecycle_0.1.0
#> [113] nlme_3.1-143 jsonlite_1.6
#> [115] Rhdf5lib_1.8.0 BiocNeighbors_1.4.1
#> [117] fansi_0.4.1 viridisLite_0.3.0
#> [119] askpass_1.1 limma_3.42.0
#> [121] BSgenome_1.54.0 pillar_1.4.3
#> [123] lattice_0.20-38 fastmap_1.0.1
#> [125] httr_1.4.1 interactiveDisplayBase_1.24.0
#> [127] glue_1.3.1 qlcMatrix_0.9.7
#> [129] FNN_1.1.3 BiocVersion_3.10.1
#> [131] bit_1.1-15.1 stringi_1.4.5
#> [133] HDF5Array_1.14.1 blob_1.2.1
#> [135] BiocSingular_1.2.1 AnnotationHub_2.18.0
#> [137] memoise_1.1.0